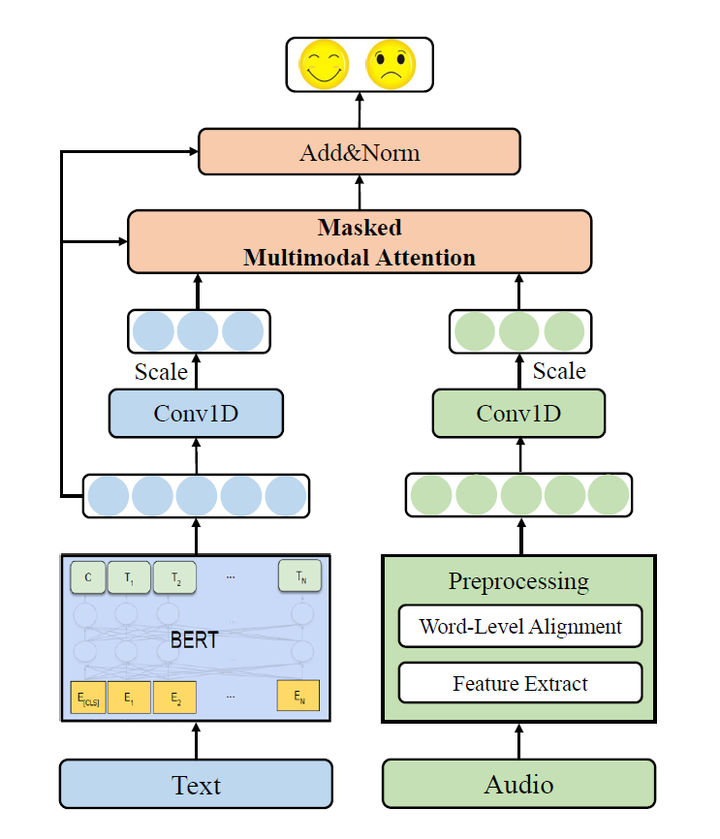
Abstract
Multimodal sentiment analysis is an emerging research field that aims to enable machines to recognize, interpret, and express emotion. Through the cross-modal interaction, we can get more comprehensive emotional characteristics of the speaker. Bidirectional Encoder Representations from Transformers (BERT) is an efficient pre-trained language representation model. Fine-tuning it has obtained new state-of-the-art results on eleven natural language processing tasks like question answering and natural language inference. However, most previous works fine-tune BERT only base on text data, how to learn a better representation by introducing the multimodal information is still worth exploring. In this paper, we propose the Cross-Modal BERT (CM-BERT), which relies on the interaction of text and audio modality to fine-tune the pre-trained BERT model. As the core unit of the CM-BERT, masked multimodal attention is designed to dynamically adjust the weight of words by combining the information of text and audio modality. We evaluate our method on the public multimodal sentiment analysis datasets CMU-MOSI and CMU-MOSEI. The experiment results show that it has significantly improved the performance on all the metrics over previous baselines and text-only finetuning of BERT. Besides, we visualize the masked multimodal attention and proves that it can reasonably adjust the weight of words by introducing audio modality information.