Abstract
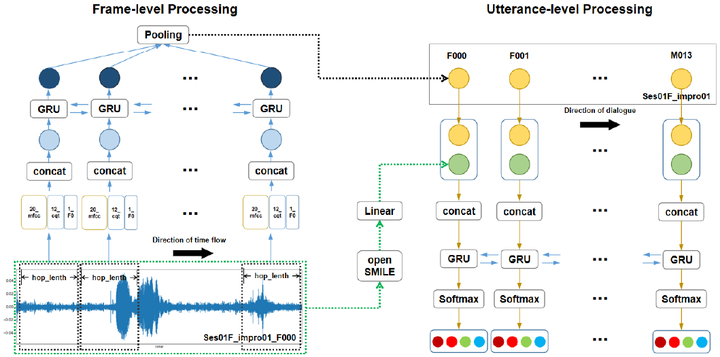
To solve the problem of poor classification performance of multiple complex emotions in acoustic modalities, we propose a hierarchical grained and feature model (HGFM). The frame-level and utterance-level structures of acoustic samples are processed by the recurrent neural network. The model includes a frame-level representation module with before and after information, a utterance-level representation module with context information, and a different level acoustic feature fusion module. We take the output of frame-level structure as the input of utterance-level structure and extract the acoustic features of these two levels respectively for effective and complementary fusion. Experiments show that the proposed HGFM has better accuracy and robustness. By this method, we achieve the state-of-the-art performance on IEMOCAP and MELD datasets.